Swahili – Language Recipe
Crawled corpora
A total of 3,751 websites were crawled for Swahili using wget.
From the initial list of websites, 519 were not available at the time of crawling. Crawling was limited to 12 hours per website. The bilingual lexicon for document alignment was built on the concatenation of the following parallel corpora: EUBookshop v2, Ubuntu, and Tanzil. A total of 180,520 pairs of documents were aligned, from which 2,051,678 segment pairs were extracted.
For the bicleaner model, the regressor was trained on the parallel corpus GlobalVoices2015 available at OPUS. The threshold for the score provided by the regressor was set to 0.68. Bicleaner’s character-level language model was trained on the same corpora used to build the bilingual lexicons and the threshold was set to 0.5. The resulting parallel corpus consisted of 156,061 segment pairs.
As a by-product of the crawling, a Swahili monolingual corpus containing 13,073,458 sentences was obtained. This corpus is the result of cleaning a larger one by applying automatic language detection and discarding sentences with less than 50% of alphanumeric characters. We have published a paper (Sanchez-Martinez et al., 2020) which fully describes the preparation of this corpus and its use for training NMT systems.
Integration Report
Translation Model Details
Corpora
Tables 1 and 2 describe the parallel and monolingual corpora we used, respectively. As regards parallel corpora, with the exception of GoURMET and SAWA, all of them were downloaded from the OPUS website. We used two additional parallel corpora: the SAWA corpus (De Pauw et al., 2011), that was kindly provided by their editors, and the GoURMET corpus, that was crawled from the web as described by Sanchez-Martınez et al. (2020). As regards the monolingual corpora, only three monolingual corpora were used: the NewsCrawl (Bojar et al., 2018a) for English, the NewsCrawl for Swahili (Barrault et al., 2019), and the GoURMET monolingual corpus for Swahili. The first two corpora were chosen because they belong to the news domain, the same domain of application of our NMT systems. Given that the size of the Swahili monolingual corpus is much smaller than the size of the English monolingual corpus, additional monolingual data obtained as a by-product of the process of crawling parallel data from the web was used for Swahili.


Preprocessing
Part of the GlobalVoices corpus was reserved for its use as development and test corpora. The remaining sentences from GlobalVoices-v2015 and GlobalVoices-v2017q3, together with the other parallel corpora listed in Table 1 were deduplicated to obtain the final parallel corpus used to train the NMT systems. All corpora were tokenised with the Moses tokeniser (Koehn et al., 2007a) and truecased. Parallel sentences with more than 100 tokens in either side were removed. Words were split in sub-word units with byte pair encoding (BPE; Sennrich et al. (2016c)). Table 3 reports the size of the corpora after this pre-processing.
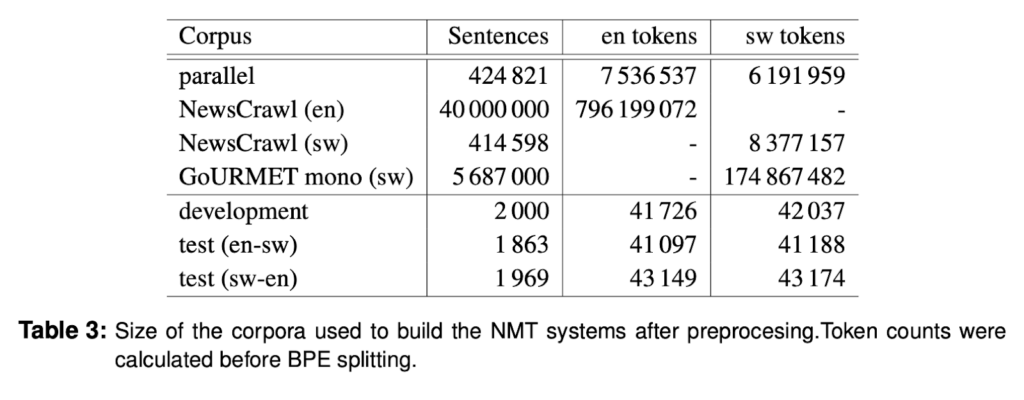
Language resources
We interleaved (Nadejde et al., 2017) linguistic tags in the target language side of the training corpus with the aim of enhancing the grammatical correctness of the translations. Morphological taggers were used to obtain the interleaved tags added to the training corpus. The Swahili text was tagged with TreeTagger (Schmid, 2013). We used a publicly available model which was trained on the Helsinki Corpus of Swahili. The English text was tagged with the Stanford tagger (Qi et al., 2018), which was trained on the English Web Treebank (Silveira et al., 2014). While the tags returned by the Swahili tagger were just part-of-speech tags, English tags contained also morphological inflection information. Interleaved tags are removed from the final translations produced by the system.
Model architecture and training
We trained the NMT models with the Marian toolkit (Junczys-Dowmunt et al., 2018). Since hyperparameters can have a large impact in the quality of the resulting system (Lim et al., 2018; Sennrich and Zhang, 2019), we carried out a grid search in order to find the best hyper-parameters for each translation direction. We explored both the transformer (Vaswani et al., 2017) and recurrent neural network (RNN) with attention (Bahdanau et al., 2014) architectures. Our starting points were the transformer hyper-parameters described by Sennrich et al. (2017) and the RNN hyperparameters described by Sennrich et al. (2016a). For each translation direction and architecture, we explored the following hyper-parameters:
- Number of BPE operations: 15 000, 30 000, or 85 000.
- Batch size: 8 000 tokens (trained on one GPU) or 16 000 tokens (trained on two GPUs).
- Whether to tie or not input embedding layers for both languages and output layer.
We trained a system for each combination of hyper-parameters, using only parallel data. Early stopping was based on perplexity on the development set and patience was set to 5 validations, with a validation carried out every 1, 000 updates. We selected the checkpoint that obtained the highest BLEU (Papineni et al., 2002) score on the development set.
We obtained the highest BLEU scores on the test set for English–Swahili with an RNN architecture, 30 000 BPE operations, tied embeddings for both languages and single GPU, while the highest ones for Swahili–English were obtained with a Transformer architecture, 30 000 BPE operations, tied embeddings for both languages and two GPUs. This is compatible with the findings by Popel and Bojar (2018), who report that transformer usually performs better with larger batch sizes.
Leveraging monolingual data
Once the best hyper-parameters were identified, we tried to improve the systems by making use of the monolingual corpora via back-translation. The quality of a system trained on back-translated data is usually correlated with the quality of the system that translates the target language monolingual corpus into the source language (Hoang et al., 2018, Sec. 3). We took advantage of the fact that we are building systems for both directions and applied an iterative back-translation (Hoang et al., 2018) algorithm that simultaneously leverages monolingual Swahili and monolingual English data.
It can be outlined as follows:
- With the best identified hyper-parameters for each direction we built a system using only parallel data.
- English and Swahili monolingual data were back-translated with the systems built in the previous step.
- Systems in both directions were trained on the combination of the back-translated data and the parallel data.
- Steps 2–3 were re-executed 3 more times. Back-translation in step 2 was always carried out with the systems built in the most recent execution of step 3, hence the quality of the system used for back-translation improved with each iteration.
The Swahili monolingual corpus used in step 2 was the GoURMET monolingual corpus. The English monolingual corpus was a subset of the NewsCrawl corpus, the size of which was doubled after each iteration. It started at 5 million sentences and reached 40 million in the fourth iteration, which was the last one.
Since the Swahili NewsCrawl corpus was only made available near the end of the development of our MT systems, it could not be used during the iterative back-translation process. Nevertheless, we added it afterwards: the Swahili NewsCrawl was back-translated with the last available Swahili–English system obtained after completing all the iterations, concatenated to the existing data for the English–Swahili direction and the MT system was re-trained.
Indicators of quality
Table 4 shows the BLEU and chrF++ (Popovic, 2017) scores expressed as a percentage, computed on the initial test set, for the different steps in the development of the MT systems. It is worth noting the positive effect of adding monolingual data during the iterative back-translation iterations and that interleaved tags also help to improve the systems according to the automatic evaluation metrics.

Initial Progress Report on Evaluation
Swahili Test set: The development and test sets were obtained from the GlobalVoices parallel corpus. 4 000 parallel sentences were selected from the concatenation of GlobalVoices-v2015 and GlobalVoicesv2017q3, and randomly split into two halves (with 2 000 sentences each), which were used respectively as development and test corpora. The half reserved to be used as test corpus was further filtered to remove the sentences that could be found in any of the monolingual corpora.
Summary of the results: We evaluate on the GlobalVoices test set. Our systems are quite strong, performing similarly to Google Translate for the Sw – En direction and better for the En – Sw direction. The user evaluation dataset consists of DWtranslated content specifically curated for this purpose, resulting in a set of 210 fully parallel sentences.
Data driven evaluation
Automatic evaluation assesses the quality of a machine translation system by automatically comparing its output translations to reference translations. This enables a quick, cost-effective and reproducible evaluation of a system since, unlike human evaluation, it does not require annotators to directly assess the outputs of the system.
Direct Assessment / Human Evaluation
Human evaluation indicators involve the participation of humans and either collect subjective feedback on the quality of translation or measure human performance in tasks mediated by machine translation. Wherever possible, manual evaluation undertaken within the GoURMET project uses in-domain data, i.e. test data derived from news sources.
Direct assessment is carried out when English is the source language, machine-translated into a non-English target.
The results of human evaluation (Gap Filling and Direct Assessment) are contained in this section.
Gap Filling
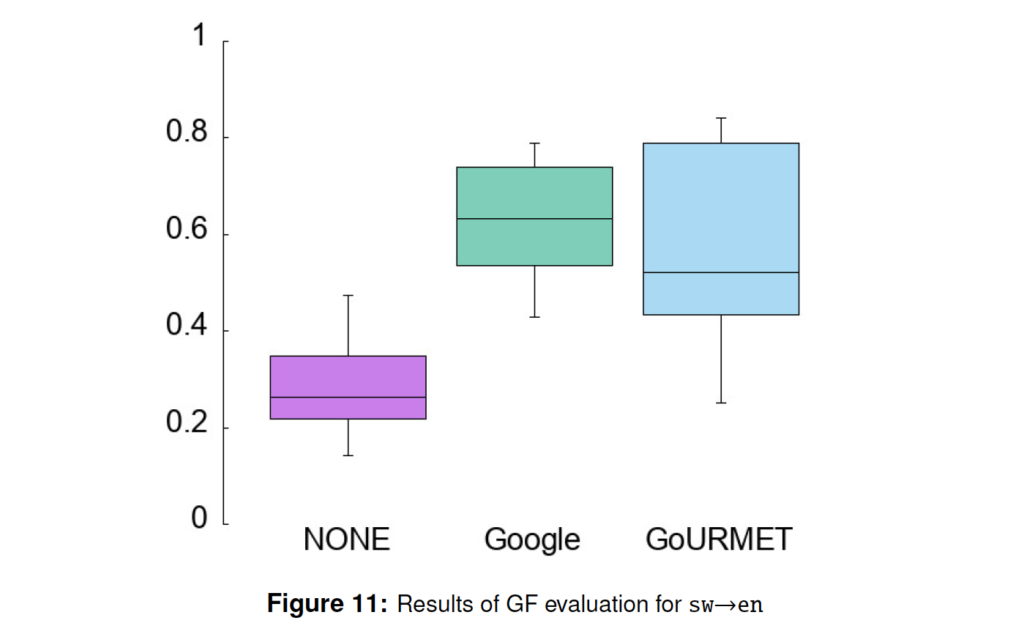
The statistics for the GF evaluation for sw – en are shown in Table 10. The detailed box plot of
results is shown in Figure 11. As may be seen, the boxes for Google and GoURMET clearly overlap, meaning that the dierence in usefulness is not significant. However we also notice a slight overlap between the GoURMET box and the maximum success-rate of the baseline (NONE); this overlap does not occur with Google Translate.

Direct Assessment
The results of the DA evaluation for language pair en- sw are shown in Figure 18 for evaluation question Q1 and Figure 19 for evaluation question Q2. User comments Representative user comments for en – sw are as follows.
A number of comments suggested the MT system was creating overly long sentences with a degradation in quality:
- Some sentences are too long to sustain actual meaning when translated.
- Some sentences are too long so the translations lose meaning.
- The shorted the sentences were, the more correct they tended to be.
- Although, according to the information above, sentences in black were written by persons, […] in some cases they were either confusing, or made no sense at all.
- What In have observed is that it only a few cases where the two sentences carried the same meaning, at the same time both being grammatically correct. Although, according to the information above, sentences in black were written by persons, they were the ones which mostly diverted from the original meaning, and in some cases they were either confusing, or made no sense at all.
General comments on the quality of the MT included:
- My general impression is that this machine is still very far from being accurate or at least coming close to correct and accurate translation. Most of the sentences were grammatically wrong and distorted the real meaning of what is really intended. There were too many distortions in the translations. I also noticed some sentences were mixing Kiswahili and English words; this does not make any sense at all in translation because the intended message is not delivered. I would not at the moment recommend the use of this translation engine but rather encourage further research with the aim of developing and improving it further.
- The general point of note for me is that some of the machine-generated sentences did not capture the meaning of the sentences that were written but people. But I generally found most of the machine-generated sentences to be grammatically and idiomatically correct.
- In many cases the machine tried to put everything in Kiswahili, where as the person in several cases used English words in sentences. At times the senences [sic] completely dier but then the person writes a more meaningful sentence than a machine.
- Some Sentence Twos [the MT sentence] had words missing.


Software
The software tools used for running the gap-filling and direct-assessment evaluations have been
released by the project as open source.
Credits: Cover Photo by Jeff Sheldon on Unsplash